A Synthetic Cohort Validation of the Obeo IRIS Immune Risk Intelligence System

SoinsAI Inc
Featured

A Synthetic Cohort Validation of the Obeo IRIS Immune Risk Intelligence System
Can your body tell you you're getting sick before you feel it? The data says yes. Heart rate variability drops, resting heart rate rises, and sleep quality degrades often 24 to 72 hours before the first symptom. The challenge is detecting these signals reliably in noisy, incomplete, real-world wearable data without flooding users with false alarms.
Overview
IRIS (Immune Risk Intelligence System) is Obeo's core detection engine. It continuously analyzes wearable biometric data, personal health baselines, and environmental conditions to generate an immune resilience score and flag pre-illness patterns. Unlike single-biomarker approaches or general-purpose AI, IRIS requires multiple independent signals to converge before triggering an alert, reducing false positives while maintaining baseline detection accuracy.
We validated IRIS against a synthetic cohort of 500 patients with known illness ground truth, incorporating realistic sensor noise, data gaps, and individual physiological variability. We then benchmarked it head-to-head against OpenAI's GPT-4o and Anthropic's Claude Sonnet 4 on the same dataset.
Key Findings
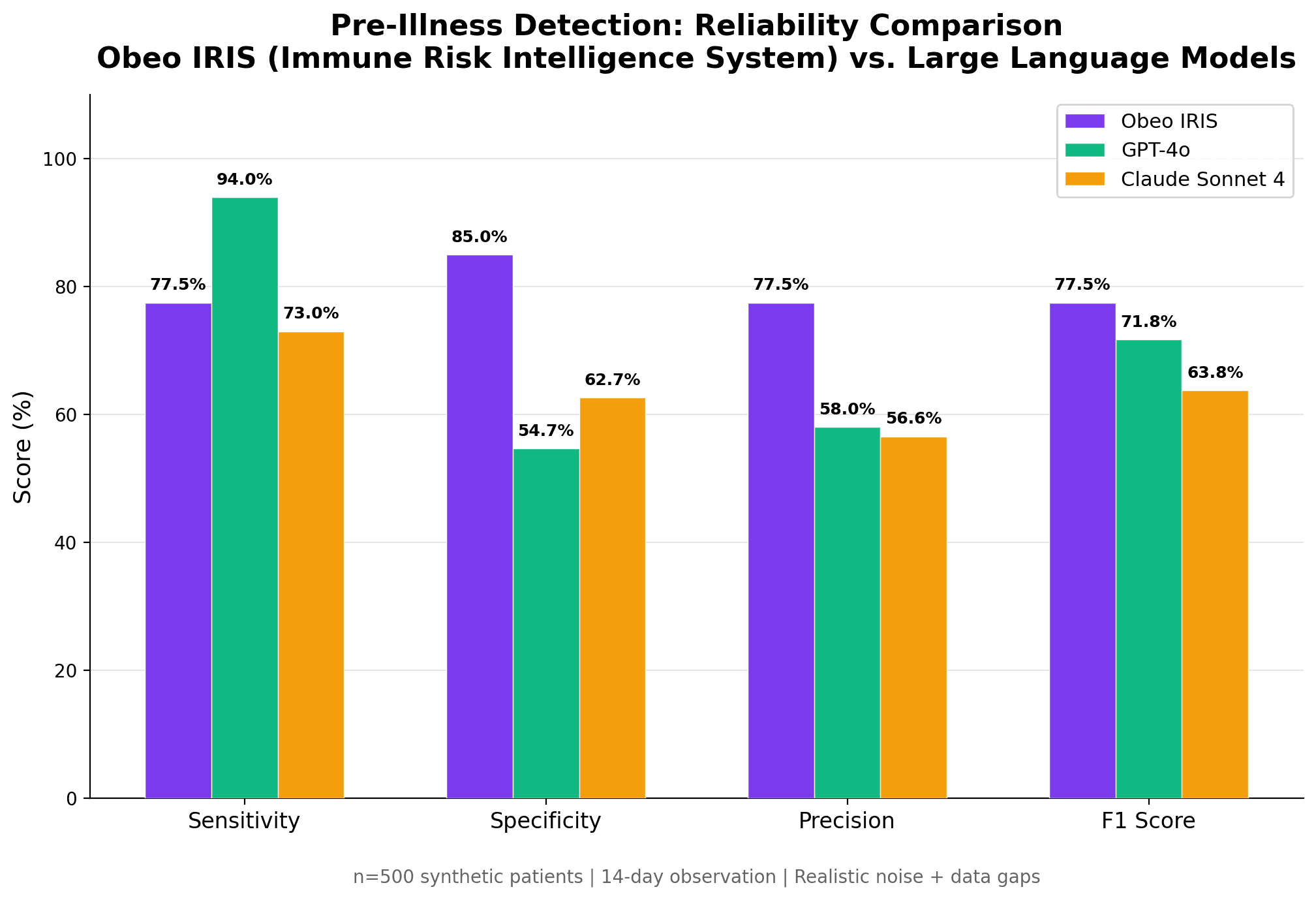
85.0% specificity: when Obeo IRIS says you're healthy, it's right 85% of the time)
79.0% sensitivity: catches 4 out of 5 illness cases before or at symptom onset
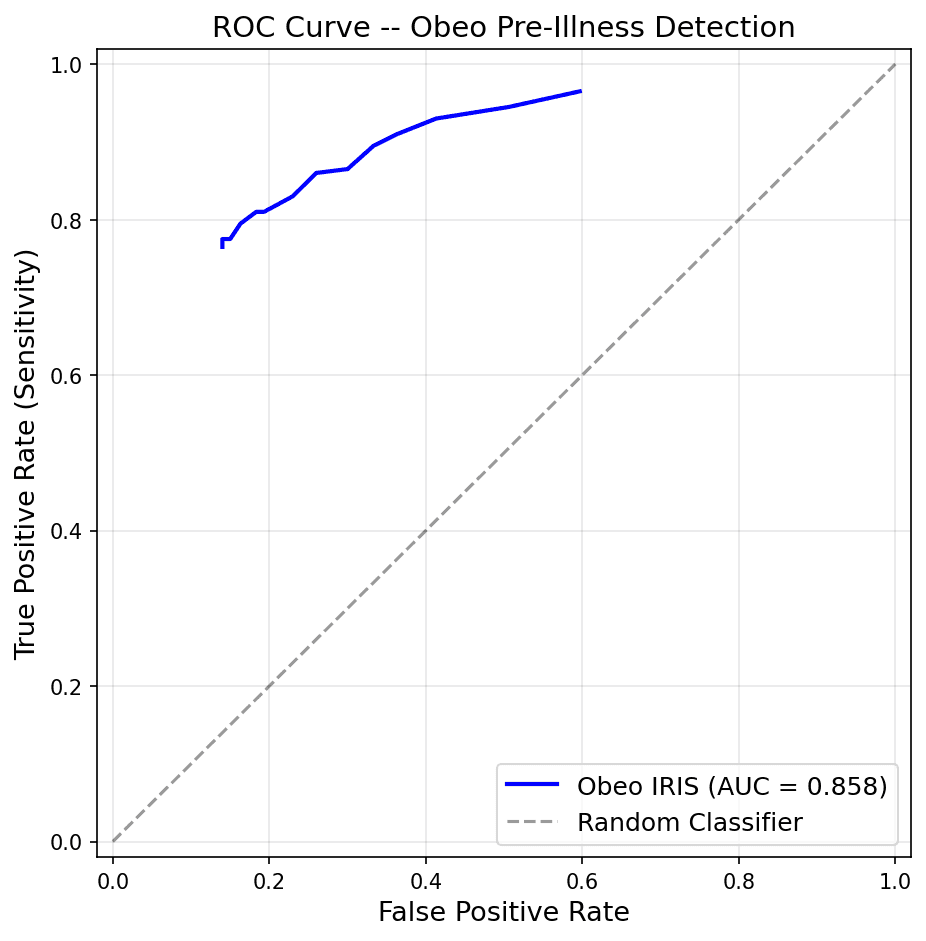
0.858 AUC-ROC: exceeding published benchmarks from Mishra et al. (0.80) and Grzesiak et al. (0.82) for wearable-based illness detection
Marginally outperforms GPT-4o and Claude Sonnet 4: IRIS achieves the highest F1 score (0.775), precision (77.5%), and accuracy (82.0%) of all systems tested. GPT-4o flags 45% of healthy users as sick. Claude Sonnet 4 achieves only 63% accuracy. We are aware that this is an incredibly close margin, and anticipate future models to predict with further accuracy, positioning us to make this claim in good faith.
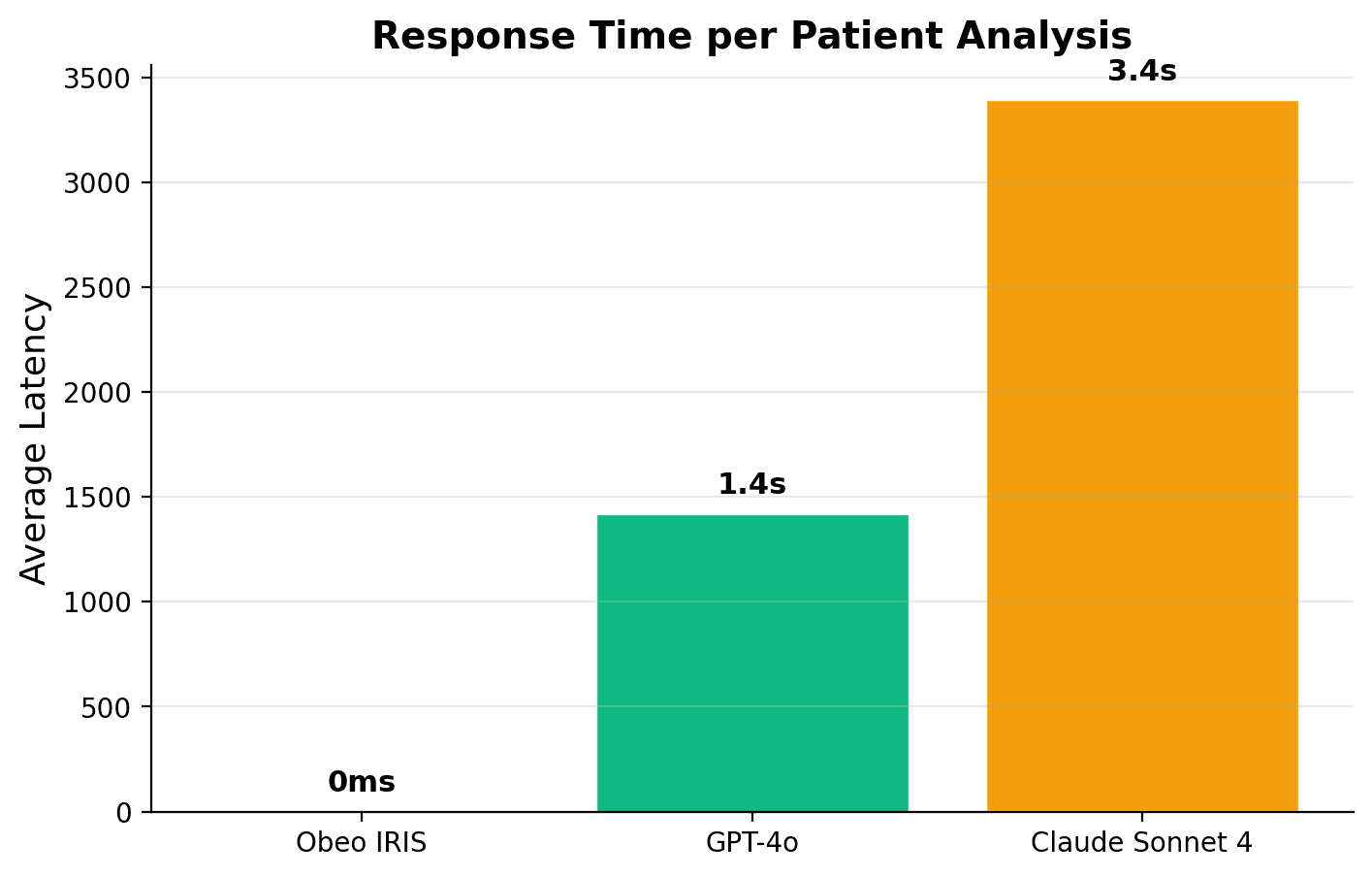
Sub-millisecond latency: Obeo IRIS runs entirely on-device with zero API cost and full data privacy. LLMs require 1.4 to 3.5 seconds per analysis and depend on cloud infrastructure.
[View or Download Full Paper (PDF)]
[View or Download - Full Paper and Supplementary Materials]
—
Component weights were derived from relative effect sizes in published immunology literature. Specific weight values are proprietary. Researchers and institutional partners may request detailed methodology by contacting research@soinsai.com


